悠悠楠杉
网站页面
本文详细讲解如何在Spring Cloud微服务架构中整合Sleuth与Zipkin实现分布式请求追踪,包含完整配置步骤、常见问题排查及生产环境优化建议。
当单体应用拆分为微服务后,一个HTTP请求可能跨越多个服务节点。某次下单操作超时,可能是订单服务、库存服务还是支付服务出了问题?传统日志排查如同大海捞针。这正是Spring Cloud Sleuth+Zipkin的用武之地:
java
// 自动为请求添加追踪信息
@Slf4j
@RestController
public class OrderController {
@GetMapping("/order")
public String createOrder() {
log.info("收到订单请求"); // 自动附加[appname,traceId,spanId,exportable]
return "success";
}
}
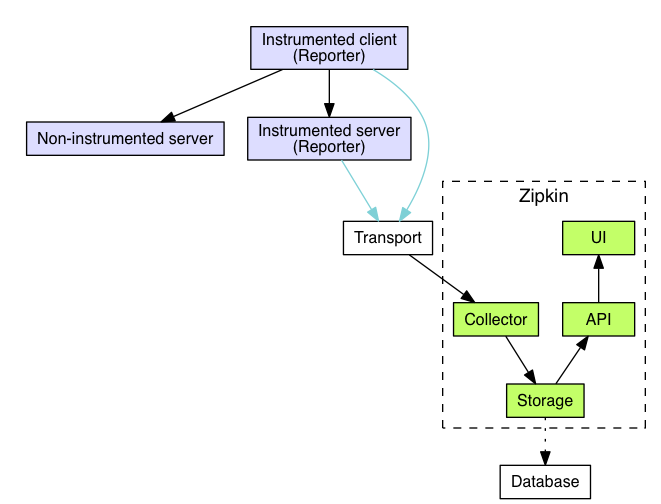
1. Transport:支持HTTP、Kafka等数据上报方式
2. Storage:可选内存、ES、MySQL存储
3. UI:提供可视化查询界面
yaml
spring:
sleuth:
sampler:
probability: 1.0 # 采样率(生产环境建议0.1)
zipkin:
base-url: http://localhost:9411
sender.type: web # 使用HTTP上报
bash
docker run -d -p 9411:9411 --name zipkin \
-e STORAGE_TYPE=elasticsearch \
-e ES_HOSTS=http://es:9200 \
openzipkin/zipkin
xml
<!-- pom.xml必须包含 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
采样率动态调整
java
@Bean
Sampler customSampler() {
return new ProbabilityBasedSampler(0.1f); // 根据QPS调整
}
存储方案选型对比
| 存储类型 | 查询性能 | 持久化 | 适用场景 |
|----------|----------|--------|------------------|
| 内存 | 最快 | 否 | 开发测试 |
| MySQL | 中等 | 是 | 小规模生产 |
| ES | 较慢 | 是 | 大规模集群 |
- 使用消息队列缓冲上报数据(建议Kafka)
- Zipkin集群化部署+负载均衡
Q1:Zipkin界面看不到数据?
- 检查spring.zipkin.base-url是否含/zipkin后缀
- 通过/actuator/httptrace端点验证数据是否生成
Q2:TraceID不连续?
- 确保所有服务时钟同步(NTP服务)
- 检查Hystrix线程池隔离配置
Q3:生产环境数据量过大?
yaml
spring.sleuth:
async:
enabled: true # 启用异步上报
web:
enabled: false # 关闭非必要WEB过滤




